
In the relentless world of mortgage lending, document chaos is the enemy within. A recent Forbes report laid bare the risks, recounting how a major lender’s outdated systems triggered a compliance catastrophe. But what if you could outsmart the chaos? DMSVu, the innovative solution from DocVu.AI, is your secret weapon. Harnessing the power of AI, it decodes unstructured data and enforces rules with surgical precision. For mortgage and BFSI leaders, DMSVu isn’t just about managing documents, it’s about mastering them. Welcome to a future where efficiency and compliance aren’t just goals, but guarantees.
How DMSVu’s decodes complex documents with ease
DMSVu leverages transformer-based NLP and multi-modal OCR to analyze layered documents, including handwritten notes and structured tables. Its adaptive neural networks recognize contextual relationships, while self-learning models improve accuracy through real-time feedback. This hybrid approach supports multilingual content, poor-quality scans, and ambiguous formats, reducing manual review by 70% and ensuring precise data extraction for compliance-driven industries like legal, healthcare, and finance.
- Layered document analysis with NLP and OCR
- Contextual understanding through advanced neural networks
- Real-time learning and model optimization
- Accurate, compliance-ready data extraction
4 key insights into DMSVu’s document intelligence

- Multi-modal OCR layering
Combines optical, textual, and layout analysis to process mixed-format documents while maintaining connections between handwritten text, images, and tables. - Contextual semantic mapping
Transformer models identify relationships between clauses or data fields, turning unstructured content into searchable, structured datasets. - Self-optimizing extraction models
Reinforcement learning adapts to new document types and languages, reducing errors by 40% after deployment without manual updates required. - Dynamic compliance anchors
Automatically detects and tags regulated data (e.g., HIPAA, GDPR) with policy-aware algorithms, enforcing retention rules and creating audit trails instantly.
The architecture behind DMSVu’s no-touch document processing
Imagine a factory where documents refine themselves. DMSVu’s architecture isn’t just code, it’s an assembly line of precision, purpose-built for industries where a single misfiled form can derail a million-dollar mortgage deal. Here’s how it works, layer by layer:
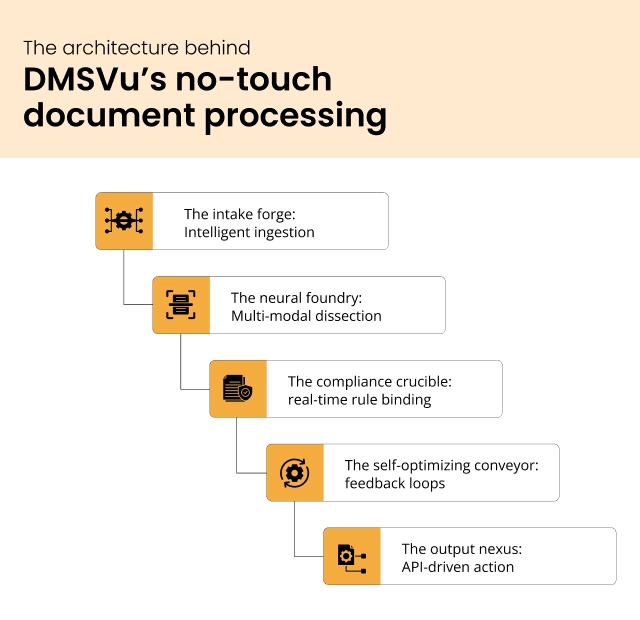
1. The intake forge: Intelligent ingestion
Documents arrive as scanned PDFs, emailed forms, and even faxes. DMSVu’s adaptive ingestion engine acts as a digital bouncer, sorting files by type, quality, and urgency. Unlike clunky legacy systems that stall on format conflicts, it deciphers crumpled scans and files (text + images) using context-aware routing.
Example: A notarized mortgage deed arrives with coffee stains. DMSVu isolates the signature block while flagging the stain for AI review.
- Adaptive multi-format ingestion
DMSVu’s engine autonomously categorizes incoming documents (scanned PDFs and files) by analyzing structural and contextual attributes. It resolves format incompatibilities inherent to legacy systems by dynamically adjusting parsing protocols without manual intervention. - Contextual hierarchical routing
Leveraging semantic analysis, the system segregates critical elements (e.g., signature blocks) from degraded or composite files (text/images). It prioritizes metadata and visual markers to route components to appropriate validation workflows, bypassing format fragmentation. - Automated anomaly prioritization
Physical document defects (e.g., coffee stains) are isolated via pixel-pattern recognition and flagged for AI audit without disrupting ingestion. Concurrently, urgency algorithms ensure unblemished sections advance through processing pipelines, maintaining throughput integrity.
2. The neural foundry: Multi-modal dissection
Documents are more than just words on a page. They carry stories, intent, and critical context. DMSVu’s patented triple-layer OCR doesn’t simply extract text. It understands, interprets, and transforms document processing into an intelligent and intuitive experience.
- Redefining OCR technology
Unlike traditional OCR that stops at basic text capture, DMSVu brings a forensic-level understanding to every document. It ensures even the subtlest detail is accurately identified and contextualized. - Precision at the visual level
Every pixel is scanned to detect faint ink, align skewed text, and preserve the integrity of visual data. This meticulous approach sets the stage for reliable analysis. - Understanding document structure
Rather than viewing text in isolation, DMSVu reads the structure of a document. It understands relationships such as the positioning of a signature near a notary stamp, concluding intent and authenticity. - Interpreting true meaning
DMSVu goes a step further by using AI and domain-trained intelligence to grasp the deeper meaning behind the text. It recognizes industry-specific terms and interprets them in context, such as understanding that ARM refers to an adjustable-rate mortgage in lending documents.
3. The compliance crucible: real-time rule binding
In the moment data is extracted, DMSVu’s intelligent policy engine activates. It instantly evaluates content against a dynamic regulatory graph, ensuring compliance from every angle.
- Navigating complex regulations
The system cross-references local lending laws, international standards like GDPR and SOC2, and client-specific mandates such as Fannie Mae guidelines. - Detecting and isolating risks
Any non-compliant clauses are automatically identified and quarantined before they reach downstream processes, reducing the risk of regulatory breaches. - Creating built-in accountability
Every compliance action is logged in real time, generating detailed audit trails. This creates a self-sustaining legal shield that supports both internal governance and external scrutiny.
4. The self-optimizing conveyor: feedback loops
Every time an error is corrected, DMSVu gets smarter. Through reinforcement learning, it continuously adapts to changing inputs, behaviors, and regulations.
- Adapting to human handwriting
The system fine-tunes its recognition capabilities to better understand individual writing styles, like the unique scribbles of loan officers. - Responding to regulatory change
As policies evolve, DMSVu dynamically updates its compliance thresholds to stay aligned with the latest legal requirements. - Focusing on what matters most
High-risk document types, such as promissory notes, are automatically prioritized for deeper analysis and stricter checks.
5. The output nexus: API-driven action
Once data is processed and validated, DMSVu doesn’t wait. It moves seamlessly into action, driving real-time outcomes across the mortgage lifecycle.
- Powering loan origination
Extracted data flows directly into loan origination systems, accelerating application processing without manual touchpoints. - Streamlining underwriting
Key insights and verified fields integrate with underwriting workflows, enabling faster, more informed decision-making. - Fueling compliance and audits
All relevant data is pushed into audit repositories, ensuring traceability and readiness for regulatory reviews.
Why this matters for mortgage leaders
Traditional DMS architectures crack under the weight of “what-ifs” (What if the scan is blurry? What if the clause is non-compliant?). DMSVu’s stack isn’t built to manage documents, it’s engineered to dissolve operational friction at scale.
The result? Self-processing loan files, faster cycles and a team focusing on what really matters, closing deals, not correcting paperwork.






